PaddleDetection 模型训练笔记
本文写的应该比较细了,首先介绍环境的搭建,然后以一个算法为例具体讲解训练过程,其他算法类似,而且 PaddleDetection 官方文档写的也很详细,有问题可以第一时间查看官方的文档!
本文描述的是使用 Nvidia GPU 的操作步骤。
1. 环境搭建
- 为了考虑 python 的兼容性,使用最新版本的 python 3.7,即 python 3.7.9。
- 使用更轻量级的 conda 工具包 Miniconda 来管理虚拟环境。
如果已经有了 python 的虚拟环境工具,比如 anaconda,这里推荐 anaconda 或 miniconda,可以直接跳过
1.1 小节!
后续无特殊说明,均在有 Nvidia GPU 的服务器上操作,当然也可以在本地有显卡的 linux 环境下操作。
1.1 python 环境
-
远程连接服务器 remote-server,这里 remote-server 为远程服务器:
ssh remote-server -
打开 Miniconda 页面,找到最新的 64 位的 linux 下的安装包复制链接,写本文时的 64位 linux 版本为:
https://repo.anaconda.com/miniconda/Miniconda3-py39_4.9.2-Linux-x86_64.sh:wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.9.2-Linux-x86_64.sh -
为下载的 miniconda 包添加运行权限:
chmod +x Miniconda3-py39_4.9.2-Linux-x86_64.sh -
运行安装包启动安装流程:
./Miniconda3-py39_4.9.2-Linux-x86_64.sh,随后按Enter键,后打开一个协议文件-
按
Ctrl+d组合键进行翻页,一直翻页,会有提示问是否接受协议内容 -Do you accept the license terms?[yes|no],输入yes按回车键Enter即可 -
之后后询问你安装位置,默认是在自己
HOME目录下的miniconda3中,这里我一般是加个.隐藏目录,所以我一般使用用户目录下的.miniconda3即/home/tianye/.miniconda3,根据自己的情况改成自己的HOME即可,然后继续Enter,等待安装即可 ⌛️ -
一段时间后会继续有提示问题 -
Do you wish the installer to initialize Miniconda3 ny running conda init? [yes|no]这里输入 yes 直接回车 -
Ctrl + d断开 SSH 连接,重新连接远程机器ssh remote-server,此时就能使用 conda 了,which conda应该就能看打印出 conda 的安装路径; -
为了加速 conda 安装包的速度,可以配置使用国内的清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --set show_channel_urls yes
-
1.2 paddle 环境
1.2.1 创建虚拟环境
重新连接远程机器后,默认会激活 conda 的 base 环境,默认是 python 3.9 的环境,我们要使用 python 3.7.9 ,所以需要新建一个虚拟环境,执行命令 conda create -n paddle python=3.7.9
-n paddle指定虚拟环境名称为 paddle,这个名称随意,最好是自己能记住,用于区分不同的环境python=3.7.9环境中使用 3.7.9 版本的 python
稍等 ⌛️ 一段时间后会有提示,回车直接默认 yes 即可,再 ⌛️ 一段时间即可完成虚拟环境的安装,会有提示如何激活和退出虚拟环境:
# To activate this environment, use
#
# $ conda activate paddle
#
# To deactivate an active environment, use
#
# $ conda deactivate
加速 pip 包安装速度
- 更新 pip:
pip install --upgrade pip- 配置使用国内安装源,这里使用 aliyun 的源:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
下面的步骤主要是安装 PaddleDetection 2.1 版本的环境,可以参考对应版本的环境安装说明,这里 2.1 的是 docs/tutorials/INSTALL_cn.md,如果是其它版本可以对应选择分支,找到 docs/tutorials/INSTALL_cn.md。
1.2.2 安装 paddlepaddle
激活虚拟环境:conda activate paddle,使用 which 命令查看 python 安装目录:

首先确实使用 cpu 还是 GPU,这里我们使用 Nvidia 的 GPU ,cuda 10.1 版本,根据 docs/tutorials/INSTALL_cn.md 确定安装 paddlepaddle 的命令如下:
# CUDA10.1
python -m pip install paddlepaddle-gpu==2.1.0.post101 -f https://paddlepaddle.org.cn/whl/mkl/stable.html
如果 CUDA 是其它版本,可以去 PaddlePaddle官网找对应计算平台的安装命令。
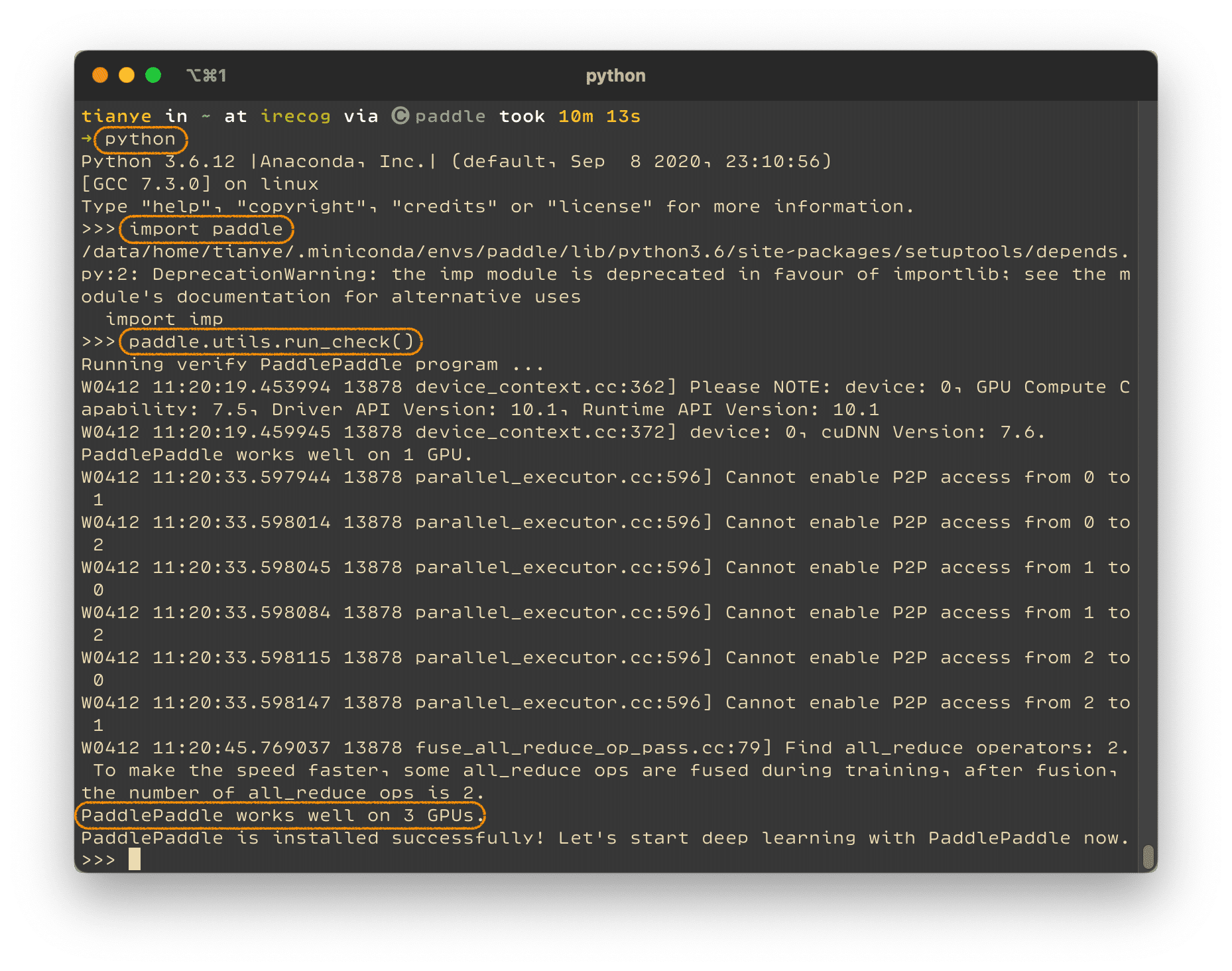
1.2.3 验证安装
安装完成后您可以使用 python 进入 python 解释器,输入import paddle ,再输入 paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装。
2. 目标检测模型训练
这里以 ppyolo 算法的模型训练为例,使用的数据集为 VOC 数据格式,使用 COCO 格式的数据集训练方式后面如果有涉及也会记录相关操作。
2.1 下载 PaddleDetection
使用最新的 PaddleDetection 代码进行目标检测,使用 git clone 到服务器适当目录即可,比如用户目录下 paddle 目录下:
# 如果没有 paddle 目录可以新建
mkdir ~/paddle
# 进入 paddle 目录
cd paddle
# 克隆 PaddleDetection 仓库
git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 可以查看下 PaddleDetection 的 1 层级目录结构
tree -L 1 PaddleDetection
此文撰写时使用的仓库的默认分支,即 release/2.1
- configs:训练的配置文件,包含各种常用的算法,我们可以复制创建自己的配置文件,进行新的训练任务
- dataset:存放标注数据,一般不要将自己的数据添加到实际的 git 跟踪中
- demo:存放一些 demo 图像,可以将我们的测试样本放到这个目录中
- output:这里一般用来存放训练导出的模型以及 demo 图像的推理结果图像
- ppdet:基于 paddlepaddle 框架的目标检测的基本库
- slim:裁剪蒸馏文件的存放位置
- tools:存放基本的模型训练、评估、推理、裁剪、生成锚框、转换数据集格式等工具脚本
- vdl_dir:可视化深度学习服务所需的文件,用于可视化训练过程
为了更好的管理自己的配置文件,建议使用好 git,这里我们可以建立自己的分支,比如我这里建立 5km 分支!
# 进入 PaddleDetection 目录
cd PaddleDetection
# 创建并切换到 5km 分支
git checkout -b 5km
2.2 数据集处理
可以使用 vocgo 切分数据集,VOC 数据集中一般会有两个目录,以数据组帮忙标注的银行大厅人员的数据为例,简单讲解下 vocgo 使用。
这里数据放在了我的用户下的 data/bank 中,首先进入这个目录:
# 进入数据目录
cd ~/data/bank
# 激活虚拟环境
conda activate paddle
2.2.1 安装 vocgo
python3 -m pip install vocgo
2.2.2 查看标注类别
一般情况下, VOC 数据的目录结构如下:

使用命令 vocgo list .即可查看当前目录下数据中标注的类别都有哪些:
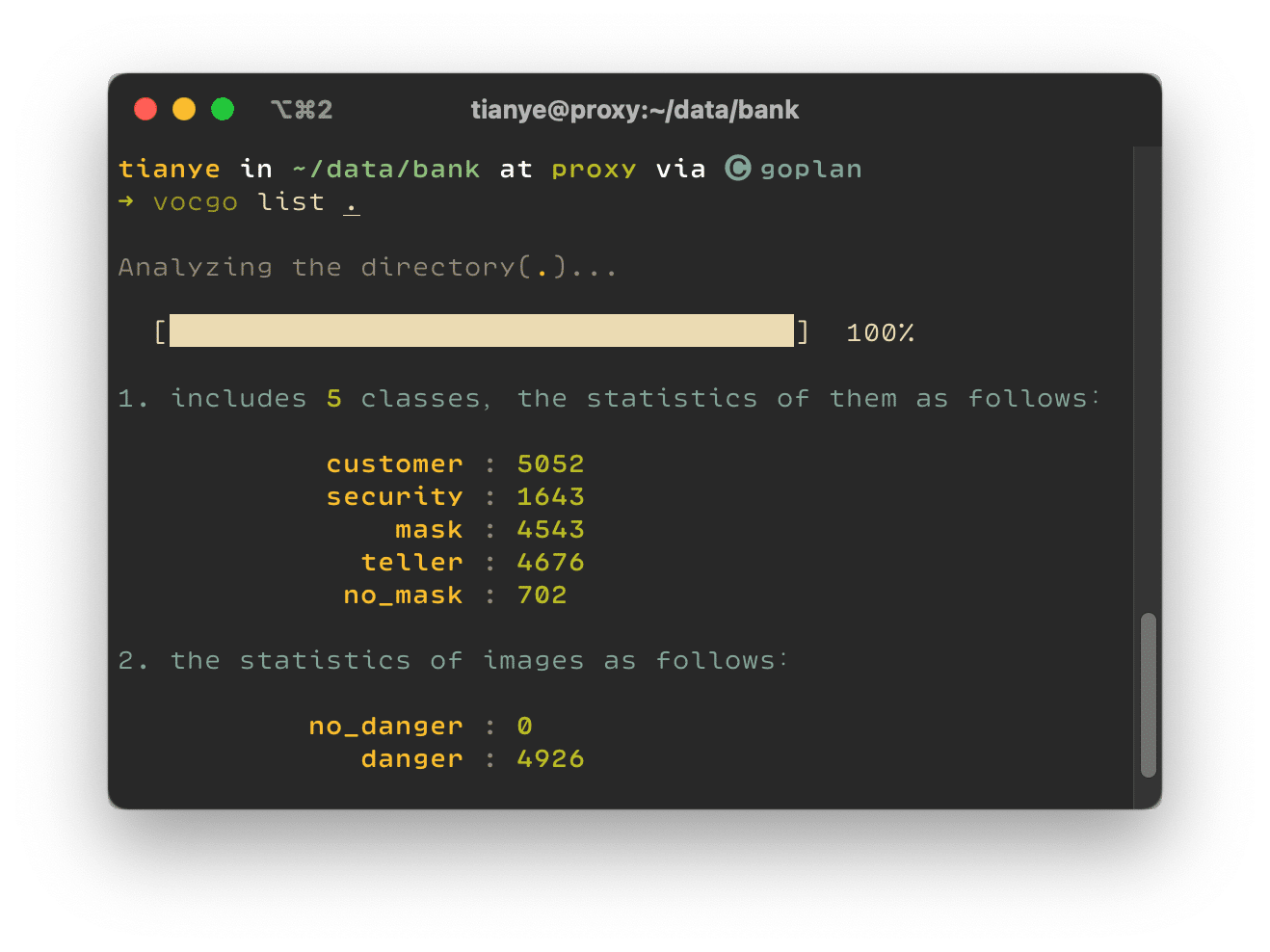
- 包含了 5 种类别的目标,也分别统计了每种类别的目标个数
- 同时也统计了有、没有检测目标的图像个数
命令中**.**指的是当前目录
2.2.3 切分数据
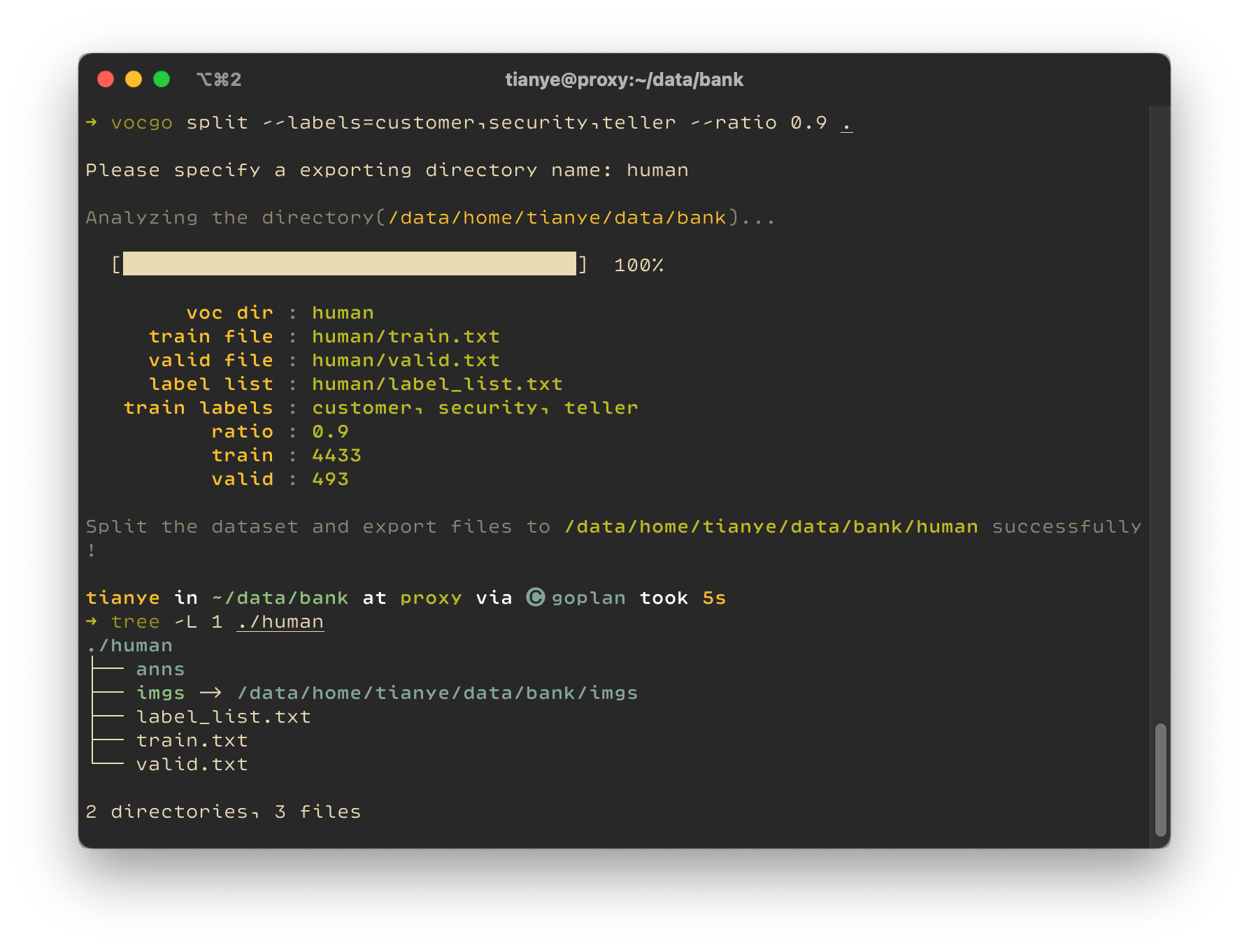
可以使用命令 vocgo split --ratio 0.9 . 对当前目录中的标注数据进行切分,其中训练集图像与验证集图像按照 比例 0.9 进行划分,执行命令后会提示输入切分数据文件的导出目录,这里我们指定为 all:

会在指定导出目录中生成相应的标注文件。
如果我们只想筛选其中的 customer、security、teller三个类别训练模型,可以通过命令vocgo split --labels=customer,security,teller --ratio 0.9 .进行数据筛选和切分,执行命令后指定导出目录为 human :
# 查看导出数据的类别
➜ cat human/label_list.txt
customer
security
teller
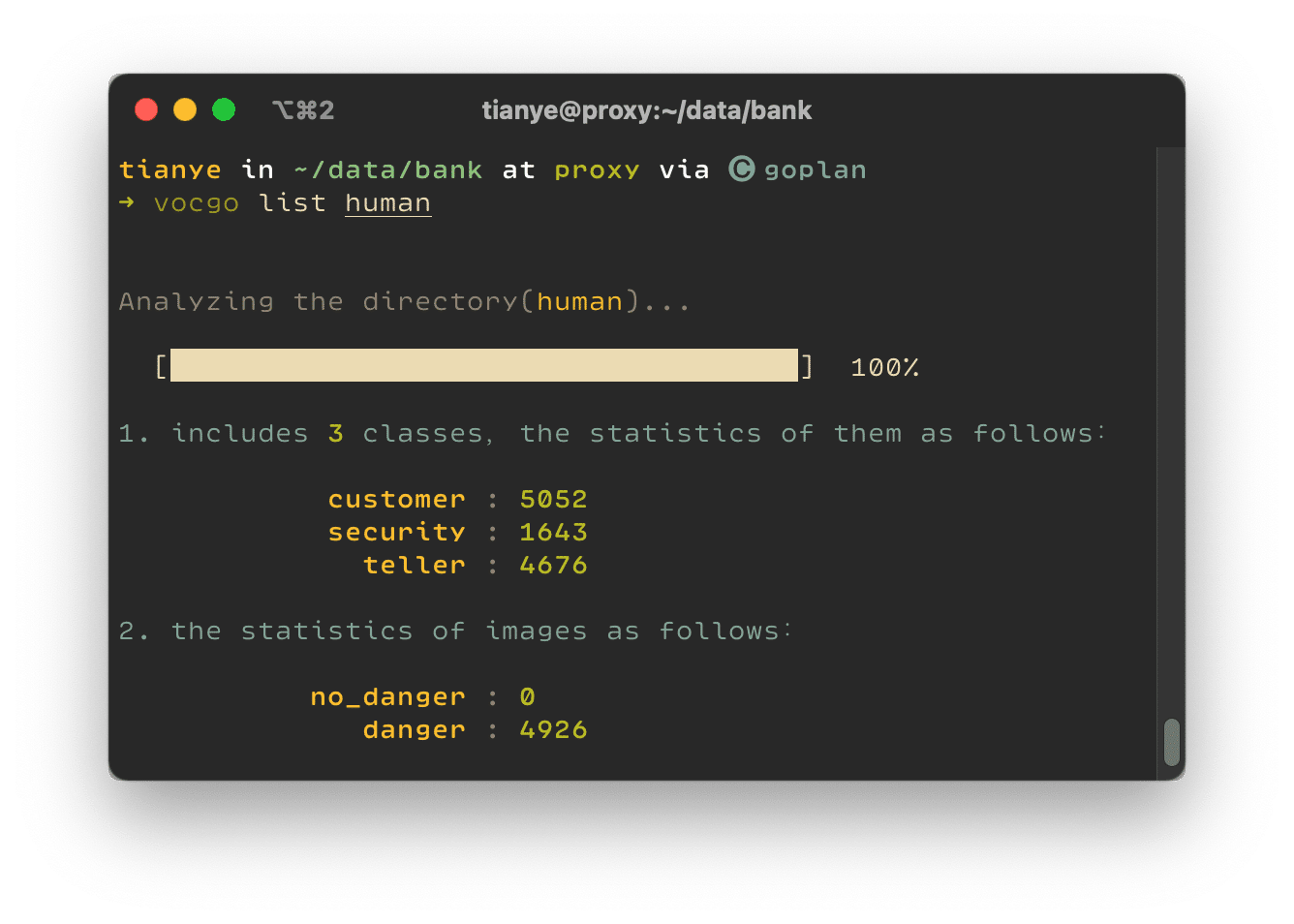
同样我们可以使用 vocgo list human 查看新导出切分数据集的类别信息:
为了不占用多余的数据空间,这里建议将我们的数据目录建立软链接到 PaddleDetection 的 dataset 目录下!
# 将 bank 目录链接到 ~/paddle/PaddleDetection/dataset/bank
ln -s ~/data/bank ~/paddle/PaddleDetection/dataset/bank
# 建议将新增的 bank 软链接添加到 PaddleDetection 仓库的 .gitignore 中
echo "dataset/bank" >> ~/paddle/PaddleDetection/.gitignore
最好是把自己添加的数据集目录都追加到 PaddleDetection 的忽略文件中!就像上面的第二条命令。
2.3 建立配置文件
我们这里使用百度 paddlepaddle 团队自研算法训练模型。
仓库中自带的 ppyolo 配置文件在 configs/ppyolo中,当然我们可以直接修改已经有的配置文件,但是为了不影响原有的参考文件,我们最好是复制一份,重命名一下,比如这里我们使用的是 configs/ppyolo/ppyolo_voc.yml ,我们要用 [2.2.3 小节](#2.2.3 切分数据) 中的切分出的 human 数据进行训练,我们暂且重命名为ppyolo_bank_human_voc.yml吧:
# 复制新的配置文件
cp configs/ppyolo/ppyolo_voc.yml configs/ppyolo/ppyolo_bank_human_voc.yml
下面开始修改配置文件,这里只简单说几项关键的参数。首先我们明确一下要使用几个 GPU,比如我们使用 4 个卡去训练模型(GPU_num=4)。
2.3.1 修改 batch_size
这个指的是一次显卡加载的图像样本数量,这受到显存的限制,默认使用的是 12,默认值对应的是 32GB 显存的卡 Tesla V100,我们的卡显存是 12GB 的 2080Ti,所以需要调小一点,比如使用 4,有一定的线性关系,当看着还有显存的时候,可以慢慢上调,比如 6,这里我们就使用 4。这个在 TrainReader的batch_size设置。
2.3.2 修改 max_iters
ppyolo 中不使用 epoch_size 表示迭代,而是使用 max_iters表示,这里我们默认 epoch_size=120,可以使用以下关系式去设置参数值:
在 [2.2.3 小节](#2.2.3 切分数据) 切分数据的时候,可以看到 human 数据集中图像数量(image_num)是 4926, [2.3.1 小节](#2.3.1 修改 batch_size) 中调整 batch_size 为 4,GPU_num 为 4,最后计算如下:
这里我们就取个整 36000 吧!
# image_num * epoch_size / GPU_num / batch_size
# 4926 * 120 / 4 / 4 => 36000
max_iters: 36000
2.3.3 调整日志打印间隔
为了更细的看到迭代过程中的结果,将 log_smooth_window和log_iter由原来的 20 改为 5。
log_smooth_window: 5
log_iter: 5
2.3.4 设置快照间隔 snapshot_iter
此参数表示每多少次保存一版模型,这里设置 3000,最终算下来能保存 12 个。
snapshot_iter: 3000
2.3.5 设置模型目录
此参数为设置模型权重文件的最终名称,其实是变相的设置输出目录,一般是设置在 output 下,即:
save_dir: output
训练过程中,会在指定的 save_dir 下生成与配置文件同名目录 -
ppyolo_bank_human_voc,中间过程即 [2.3.4 小节](#2.3.4 设置快照间隔 snapshot_iter) 中设置保存的每一版模型都会存储到该目录中。
这里要特别说一下 weights 参数,这个参数一般用于模型转换和模型推理,用于指定转换的输入模型,模型训练完成后最终的模型名称就是 model_final,我们可以指定为下面的配置:
weights: output/ppyolo_bank_human_voc/model_final
2.3.6 设置类别个数
yolo 系的算法在数据集的配置中都会设置 with_background 为 false 也就是不包含背景,那么依照 [2.2.3 小节](#2.2.3 切分数据) 最后查看 human 切分数据的时候的类别个数为准,也就是 3 个:
num_classes: 3
2.3.7 设置学习率参数
- 按照百度传达的经验,调整学习率应该依据于使用 GPU 的个数 GPU_num 和设置的 batch_size,原始的
base_lr=0.01为使用 8 卡,同时batch_size设置为 12 时设置的值,因为我们使用卡数量为 4,batch_size 为 4,所以最终设置base_lr为 0.0025即可。 - 设置学习率调整的
schedulers参数,其中PiecewiseDecay的milestones设置依赖于 [2.3.2 小节](#2.3.2 设置 max_iters)中的max_iters值,两个值一般分别按比例 0.8 和 0.88(大约,周边取整即可),所以对应 36000 的话,应该是 28800 和 32000。 - 同样需要按比例调整
LinearWarmup的steps,也是依据 [2.3.2 小节](#2.3.2 设置 maxiters) 中的max_iters值,一般比例是 17.5 左右,计算取整即可,这里 $\frac{iters{max}}{17.5}=\frac{36000}{17.5}\approx2100$,所以最终配置。
LearningRate:
base_lr: 0.0025
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 28800
- 32000
- !LinearWarmup
start_factor: 0.
steps: 2100
2.3.8 设置 Reader
-
设置
_Reader_,默认值是相对于配置文件下的ppyolo_reader.yml文件,以后有可能我们还会修改里面的内容,所我们也复制这个文件,新文件命名为ppyolo_bank_human_reader.yml,同时更新_Reader_的值为ppyolo_bank_human_reader.yml。# 复制 reader 文件 cp configs/ppyolo/ppyolo_reader.yml configs/ppyolo/ppyolo_bank_human_reader.yml -
设置数据集目录,需要对训练集、评估集的
dataset_dir、anno_pathdataset_dir数据集的目录路径,相对于 PaddleDetection 的目录设置,训练集和评估集都是dataset/bank/humananno_path对应的切分数据文件,训练集的为train.txt,评估集的为valid.txt
-
设置使用我们自己生成的 label_list 文件,所以需要把
TrainReader、EvalReader、TestReader的dataset下的use_default_label设置为false。 -
对应 [2.3.1 小节](# 设置 batch_size) 中的
batch_size就是在TrainReader中设置,值为 4。
_READER_: "ppyolo_bank_human_reader.yml"
TrainReader:
dataset: !VOCDataSet
dataset_dir: dataset/bank/human
anno_path: train.txt
use_default_label: false
with_background: false
mixup_epoch: 350
batch_size: 4
EvalReader:
inputs_def:
fields: ["image", "im_size", "im_id", "gt_bbox", "gt_class", "is_difficult"]
num_max_boxes: 50
dataset: !VOCDataSet
dataset_dir: dataset/bank/human
anno_path: valid.txt
use_default_label: false
with_background: false
TestReader:
dataset: !ImageFolder
use_default_label: false
with_background: false
2.3.9 设置 Anchor
-
这里需要使用 PaddleDetection 提供的工具脚本
tools/anchor_cluster.py聚类生成对应 human 数据的 Anchor 数据:python tools/anchor_cluster.py -c configs/ppyolo/ppyolo_bank_human_voc.yml -n 9 -s 608 -m v2 -i 1000-c指定使用的配置文件,这里我们的就是刚刚修改好的配置文件configs/ppyolo/ppyolo_bank_human_voc.yml-n 9生成 9 组尺寸-s 608指定图像训练尺寸-m v2使用默认的 v2 版本方法-i 1000迭代次数
其实这里的 -c 之后的很多选项我也不知道具体明确的意思,后面有时间在探究然后补充到这里,先按照默认的选项生成!
执行上边脚本后会打印 9 组尺寸,用于替换配置文件中原有配置即可,比如我这里打印的是:

-
需要替换配置文件
configs/ppyolo/ppyolo_bank_human_voc.yml中YOLOv3Head的anchors为上面打印的 9 个尺寸列表。YOLOv3Head: anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]] anchors: [ [20, 44], [28, 108], [38, 158], [78, 123], [55, 221], [108, 152], [79, 268], [118, 326], [156, 352], ] -
因为配置项
YOLOv3Loss的use_fine_grained_loss配置为了true所以还需要设置configs/ppyolo/ppyolo_bank_human_reader.yml中的 anchor 配置,具体找到TrainReader-batch_transforms-!Gt2YoloTarget修改anchors即可:# Gt2YoloTarget is only used when use_fine_grained_loss set as true, # this operator will be deleted automatically if use_fine_grained_loss # is set as false - !Gt2YoloTarget anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]] # anchors: [[22, 47], [29, 112], [41, 170], # [75, 123], [62, 243], [106, 148], # [101, 278], [121, 384], [155, 328]] anchors: [ [20, 44], [28, 108], [38, 158], [78, 123], [55, 221], [108, 152], [79, 268], [118, 326], [156, 352], ]
到这里完成了基本的配置文件的修改,下一步就可以进行模型训练了!
本小节简单介绍了基本的常规需要调整的参数,后面如果有收获会继续丰富这个小节关于参数的调整内容。
2.4 模型训练
得益于强大的 PaddleDetection 我们只需要简单的一条命令就可以开启模型训练。
2.4.1 准备工作
训练过程一般是很长时间,然而我们 ssh 链接一旦断开就会把运行的训练程序停掉,为了防止这种情况的发生,我们一般远程 SSH 链接机器后,还会使用 tmux 创建会话,在新的会话中执行我们的命令,只要不是 tmux 挂掉或者我们自己 kill 程序,一般情况下我们的程序就会由 tmux 进行托管执行,即使我们断开了 SSH ,重新连接机器后,连接上 tmux 的会话也能看到自己也还在执行的程序,下面简单说一下我的操作过程:
-
创建会话,会话名称为 paddle
tmux new -s paddle这样就会打开一个会话并激活一个窗口 shell。
-
我一般会把窗口重命名,还会创建一个专门监控显卡和其他硬件资源的窗口,使用当前的窗口创建即可:
-
重命名窗口为 monitor:按下快捷键
ctrl+b,然后按,键就会在最低边可以编辑修改名称,改为 monitor 回车即可 -
这样回到 shell 之,执行命令
watch -n 0.5 nvidia-smi,这样就会每 0.5 秒刷新一次显卡状态 -
快捷键
ctrl+b,然后按%键,会在右侧竖分出一个新的窗格,我们可以打开一个 top 命令随时查看 CPU、memery 和 proc 情况,我这里使用的是 gotop 命令,更好看一些,直接运行命令gotop,你可以运行top或者htop,这样我们的监控窗口就做好了,晒一下我的监控窗口:
-
快捷键
ctrl+b,然后按c键,此时会创建新的窗口,按下快捷键ctrl+b,然后按,键就会在最低边可以编辑修改名称,改为 train 回车,这样我们的窗口都准备好了,窗口切换的快捷键是:快捷键ctrl+b,然后按p或n- 其中
p代表 previous 表示切换到前一个窗口 - 其中
n代表 next 表示切换到前一个窗口
- 其中
-
-
然后进入工作目录,并激活虚拟环境
# 进入 PaddleDetection 目录 cd paddle/PaddleDetection # 激活虚拟环境 conda activate paddle
2.4.2 开始训练
假设我们使用 0、1、2、3 号卡训练模型,那么执行命令
CUDA_VISIBLE_DEVICES=0,1,2,3 python tools/train.py -c configs/ppyolo/ppyolo_bank_human_voc.yml --eval -o use_gpu=true --use_vdl=True --vdl_log_dir=vdl_dir/scalar
CUDA_VISIBLE_DEVICES=0,1,2,3指定环境变量,告诉 ppdect 使用 0、1、2、3 号卡进行多卡训练tools/train.py训练工具脚本-c configs/ppyolo/ppyolo_bank_human_voc.yml使用我们刚做好的配置文件--eval每次快照保存模型的时候进行一次评估-o use_gpu=true覆盖配置文件中的指定配置项的值,这里是指定要使用 gpu--use_vdl=True配置开启深度学习可视化,可以看一些 loss 曲线,可视化训练过程中关键指标的变化--vdl_log_dir=vdl_dir/scalar指定可视化日志输出位置
正常的情况下,经过 ⌛️ 一段时间我们就能看到迭代过程中的日志打印了,类似于:
[INFO 2021-04-14 14:29:09,065 train.py:286] iter: 765, lr: 0.000607, 'loss_xy': '1.455415', 'loss_wh': '1.337777', 'loss_obj': '11.151718', 'loss_cls': '2.540418', 'loss_iou': '4.378272', 'loss_iou_aware': '0.087677', 'loss': '20.988634', eta: 6:41:24, batch_cost: 0.68355 sec, ips: 5.85182 images/sec

可以查看日志打印观察 loss 是否是收敛的。
训练起来之后可以按快捷键 快捷键 ctrl+b,然后按 p 返回到 monitor 窗口,查看硬件资源使用情况,比如显卡,可以看一下显存占用,可以作为依据调整配置文件中 batch_size。
2.4.3 可视化曲线
为了更直观的观看训练情况,我们可以开启 VDL 的服务查看动态的曲线变化。这里有个小技巧,如果直接在 ssh 连接机器的 shell 中执行启动可视化服务的命令,因为服务器的端口并未开放,我们在自己本地是无法访问的,最简单的坚决方式是使用 vscode,vscode 能自动转发连接服务器上自己启动的端口服务,这里就不讲如何使用 vscode 远程连接服务器了,自行百度。
使用 vscode 远程连接上面训练任务开启的机器,打开 paddle/PaddleDetectioj 文件夹,打开一个终端窗口,如果没有激活我们创建的 paddle 虚拟环境的话,我们自己激活即可 conda activate paddle ,然后执行以下命令启动服务,指定 vdl 的日志目录与训练命令中对应起来:
visualdl --logdir vdl_dir/scalar/
执行命令后,vscode 就会检测到新的端口服务并提示完成转发:
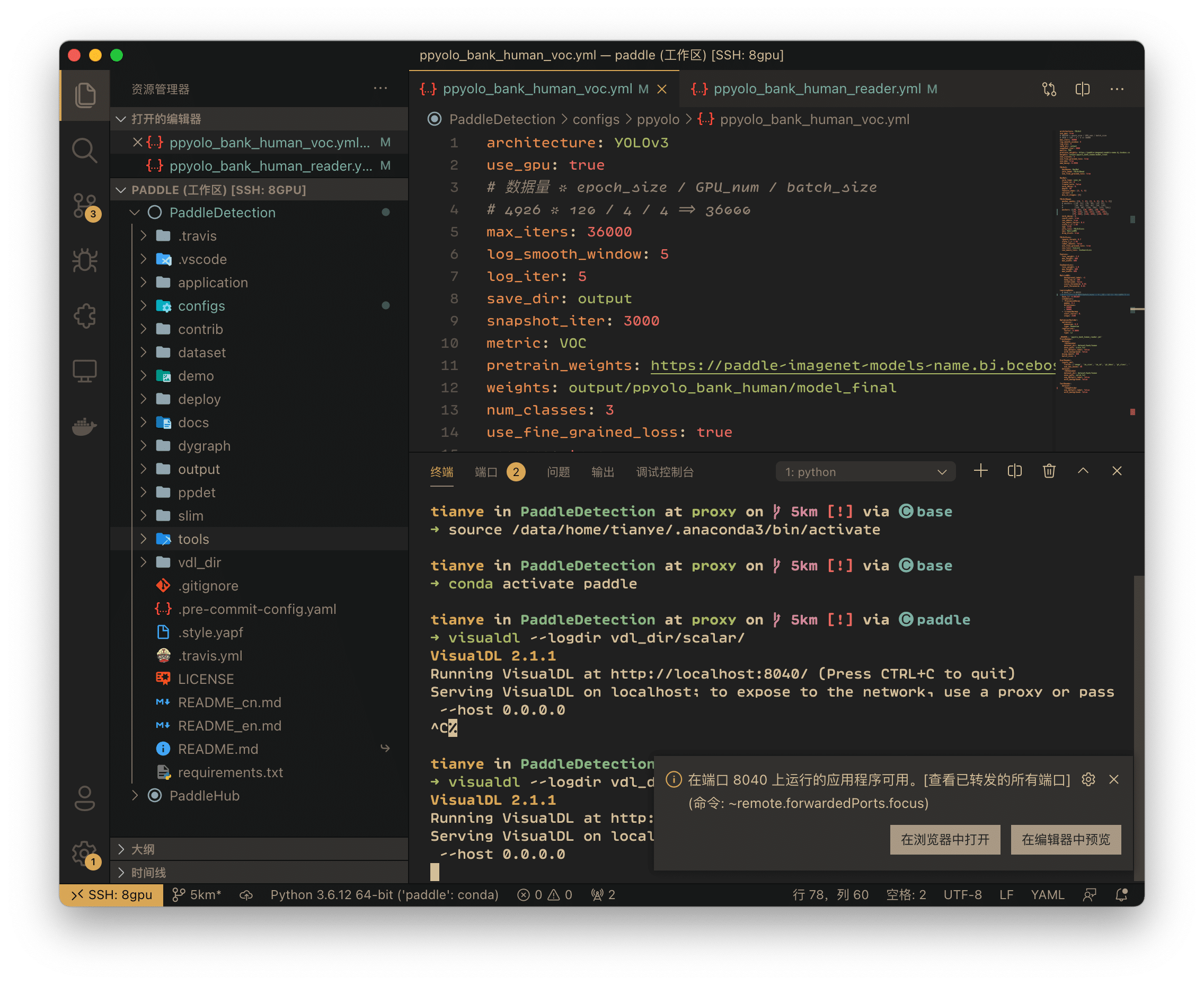
点击**「在浏览器中打开」**按钮即可在浏览器打开我们的可视化服务的页面,便可以查看各种曲线了:

2.4.4 后台运行
我们可以把 tmux 会话推到后台,使用快捷键 ctrl+b,然后按下 d 即可退出 tmux。
如果想要重新连接我们训练的会话,执行命令:
tmux a -t paddle
paddle就是我们的会话名称a是 attach 的缩写
2.4.5 等待完成
训练需要很长时间,具体大约的时间,在打印的日志中有体现,比如:
[INFO 2021-04-14 14:29:09,065 train.py:286] iter: 765, lr: 0.000607, 'loss_xy': '1.455415', 'loss_wh': '1.337777', 'loss_obj': '11.151718', 'loss_cls': '2.540418', 'loss_iou': '4.378272', 'loss_iou_aware': '0.087677', 'loss': '20.988634', eta: 6:41:24, batch_cost: 0.68355 sec, ips: 5.85182 images/sec
其中 eta 就是评估的可能耗时。
去干点其它的事情就行了,可以偶尔连接机器连接 tmux 会话查看训练情况,有可能会出问题的!
2.5 模型推理
2.5.1 一张图像推理
推理很简单,使用以下命令即可测试一张图像的推理:
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyolo/ppyolo_bank_human_voc.yml -o use_gpu=true --infer_img=demo/demo.jpg
CUDA_VISIBLE_DEVICES=0声明要使用的显卡编号,比如这里指定使用 0 号卡-c configs/ppyolo/ppyolo_bank_human_voc.yml使用我们刚做好的配置文件-o use_gpu=true覆盖配置文件中的指定配置项的值,这里是指定要使用 gpu--infer_img指定要测试的图像
这里注意的是,根据训练配置,推理会默认加载使用配置项 weights 指定的模型,这里就是 output/ppyolo_bank_human_voc/model_final,详见[2.3.5 设置模型目录](#2.3.5 设置模型目录) 。
2.5.2 多张图像推理
如果要推理一批图像,可以将图像放置在一个目录中,比如是 ./demo/bank,使用 infer.py 时指定图像目录即可:
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyolo/ppyolo_bank_human_voc.yml -o use_gpu=true --infer_dir=demo/bank
--infer_dir指定要测试的图像目录
2.5.3 其它选项
可以查看 tools/infer.py 最后的代码,自行查看。
2.6 模型部署
步骤比较清晰,要看是预测部署还是服务部署方式。
2.6.1 预测部署
2.6.1.1 导出模型
使用以下命令导出模型文件:
python tools/export_model.py -c configs/ppyolo/ppyolo_bank_human_voc.yml -o use_gpu=true --output_dir=./inference_model
tools/export_model.py导出模型的工具脚本;-c configs/ppyolo/ppyolo_bank_human_voc.yml指定配置文件--output_dir=./inference_model指定导出目录,会在此指定目录下生成与配置文件同名的目录存放导出模型文件
导出模型结构:
➜ tree inference_model/ppyolo_bank_human_voc
inference_model/ppyolo_bank_human_voc
├── infer_cfg.yml
├── __model__
└── __params__
0 directories, 3 files
可以看到只有三个文件:
infer_cfg.yml中能看到模型的关键配置信息和类别信息__model__描述网络结构__params__存储网络结构中的权重参数数据
2.6.1.2 预测
使用 deploy/python/infer.py 这个工具脚本推理即可,deploy/python 目录下三个 python 脚本,只需要这三个文件和上面导出的模型文件即可独立于 PaddleDetection 完成推理预测,支持分析指定图像以及视频文件。
-
分析图像
python deploy/python/infer.py \ --model_dir inference_model/ppyolo_bank_human_voc \ --image_file demo/xxx.jpg \ --output_dir output/bank_human/ppyolo_bank_human_voc \ --use_gpu True \ --threshold 0.5 -
分析视频
python deploy/python/infer.py \ --model_dir inference_model/ppyolo_bank_human_voc \ --video_file demo/bank_human/chlorine_bottle/demo_chlorine_bottle_ch24.mp4 \ --output_dir output/bank_human/ppyolo_bank_human_voc \ --use_gpu True \ --threshold 0.5
2.6.1 服务部署
如果我还喘气,可能还会更新。。。
我的loss一直在20,修改学习率,也没有用。老师可以帮帮我吗
写的真好, 求更推理部分内容
田老师强啊
@Anonymous ,
v1.5.2