python3 简单实现验证码识别器
编写爬虫总该要过验证码识别这个坎,今天用python3简单实现一个验证码识别器。其实主要是实践,最后效果也不是特别好,对于复杂的验证码,还是力不从心的!
开始之前,提醒⏰,应该是中间有些处理不对,造成结果不理想,不过本文的思路是可行的,因为参考的实验楼 —— python 破解验证码!
前言
其实已经有很多现成的python库可以用于识别验证码了,比如:pytesseract 和 tesseract_ocr,本文也要自己实现一种方法,最终做一个可以使用三种方法的验证码识别器。
准备工作
在开始之前需要做一些准备工作,安装必要的库和准备独立的开发环境。
- pipenv
- pytesseract
- tesseract_ocr
- pillow
这里使用独立的python环境进行开发,用到了pipenv
-
首先安装 pipenv
pip3 install pipenv -
为当前工程激活独立的python环境:
pipenv install -
进入pipenv的独立环境:
pipenv shell进入后会看到命令行每条命令输入前多了一部分信息,形如
(pin2chars-E2eD5P-4) -
在安装和使用库 pytesseract 和 tesseract_ocr 之前需要安装 tesseract:
- macOS下:
brew install tesseract - 其它系统,根据自己系统的包安装方法安装;
- macOS下:
-
然后使用
pip3安装库(库会安装在当前的激活环境中):pip3 install pipenv pytesseract tesseract_ocr pillow
pytesseract 和 tesseract_ocr 库^[python3 破解验证码]
pytesseract 和 tesseract_ocr 库都基于工具 tesseract,这两个库只需各自调用一个方法就能实现验证码的识别,非常简单。下面使用 ipython 看一下使用方法,这里准备一个验证码图片 code.gif 作为识别对象:
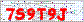
pytesseract 库识别验证码
使用库中的 image_to_string 方法传入图片的路径,比如上面的图片 code.gif 为例:
(pin2chars-E2eD5P-4) ➜ pin2chars git:(master) ✗ ipython
Python 3.7.0 (default, Sep 18 2018, 18:47:08)
In [1]: import pytesseract
In [2]: pytesseract.image_to_string('code.gif')
Out[2]: '7S9T9J’'
图像经过二值化处理的话可能效果更好一些。
tesseract_ocr 库识别验证码
使用库中的 text_for_filename 方法传入图片的路径,比如上面的图片 code.gif 为例:
(pin2chars-E2eD5P-4) ➜ pin2chars git:(master) ✗ ipython
Python 3.7.0 (default, Sep 18 2018, 18:47:08)
In [1]: import tesseract_ocr
In [2]: tesseract_ocr.text_for_filename('code.gif')
Warning. Invalid resolution 0 dpi. Using 70 instead.
Out[2]: '7S9T9J’'
图像经过二值化处理的话可能效果更好一些。
自实现库 pin_cracker
自实现方法的思路:先二值化图片,然后分割图片的单个字符图片数据,最后利用向量空间识别方法得到字符。
导入必要库:
import os
import math
from PIL import Image
二值化图片
新建文件 pin_cracker.py,自实现库的代码均存在此文件中。观察到验证码图片中,字符位置对应像素颜色是很明显的,可以先找到像素颜色最多的颜色,列出来,选择器其中正确的像素值作为阈值。
先将图片灰度化,这样每个像素点的取值范围就是 [0, 255] 了,取得像素分布直方图数据:
def get_binary_image(filename):
'''得到二值化图片数据'''
img = Image.open(filename).convert("P")
his = img.histogram()
his_10 = [(j, k) for j,k in sorted(enumerate(his), key=lambda x:x[1], reverse = True)[:10]]
print(his_10)
得到结果:
[
(255, 625),
(212, 365),
(220, 186),
(219, 135),
(169, 132),
(227, 116),
(213, 115),
(234, 21),
(205, 18),
(184, 15)
]
选择其中 220 和 227 值作为阈值。最终实现封装为函数如下:
def get_binary_image(filename):
'''得到二值化图片数据'''
img = Image.open(filename).convert("P")
# his = img.histogram()
# his_10 = [(j, k) for j,k in sorted(enumerate(his), key=lambda x:x[1], reverse = True)[:10]]
# print(his_10)
threshold = [213, 219, 220, 227]
binary_img = Image.new("P", img.size, 255)
for x in range(img.size[1]):
for y in range(img.size[0]):
pix = img.getpixel((y,x))
if pix in threshold:
# these are the numbers to get
binary_img.putpixel((y,x), 0)
return binary_img
试一下效果:
bimg = get_binary_image('code.gif')
bimg.show()

分割图片
图片比较简单,所以可以利用简单的纵向切割得到每个字符的像素范围,一列一列地判断像素值,全是1那就不是字符区,最终封装实现如下:
def slice_image(bimg):
'''通过传入的二值化图片数据进行纵向切图,得到每个字符的分割图,并返回图片数量'''
letters = []
foundletter = False
letter_start = 0
letter_end = 0
for x in range(bimg.size[0]):
pixelist = [bimg.getpixel((x, y)) for y in range(bimg.size[1])]
has_p = 0 in pixelist
if foundletter == False and has_p == True:
foundletter = True
letter_start = x
if foundletter == True and has_p == False:
foundletter = False
letter_end = x
letters.append((letter_start, letter_end))
for index, letter in enumerate(letters):
img = bimg.crop((letter[0], 0, letter[1], bimg.size[1]))
img.save(f'{index}.gif')
return len(letters)
向量空间
这里使用向量空间搜索引擎来做字符识别,它具也有优点也有缺点^[实验楼 —— python 破解验证码]:
优点:
- 不需要大量的训练迭代
- 不会训练过度
- 可以随时加入/移除错误的数据查看效果
- 很容易理解和代码实现
- 提供分级结果,可以查看最接近的多个匹配
- 对于无法识别的东西只要加入到搜索引擎中,马上就能识别
缺点:
- 分类速度慢于神经网络分类
- 找不到自己的方法解决问题
阅读Basic Vector Space Search Engine Theory 可以了解向量空间搜索引擎原理。拿文章里的例子通俗讲:要量化文档的相似度,可以比较2篇文档所使用的相同单词数量,越多的话两篇文章就越相似!单词太多了也不要紧,可以选择几个关键单词,选择的单词又被称作特征,每一个特征就好比空间中的一个维度(x,y,z等),一组特征就是一个矢量,每一个文档我们就能得到这么一个矢量,只要计算矢量之间的夹角就能得到文章的相似度了。
先实现一个向量空间类:
class VectorCompare:
def magnitude(self, concordance):
"""矢量大小"""
total = 0
for count in concordance.values():
total += count ** 2
return math.sqrt(total)
def relation(self, concordance1, concordance2):
"""矢量之间的夹角的cos值"""
topvalue = 0
for word, count in concordance1.iteritems():
if concordance2.has_key(word):
topvalue += count * concordance2[word]
return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
定义一个将图片转换为向量的方法:
def build_vector(im):
'''将图片转换为矢量'''
vector = {}
count = 0
for i in im.getdata():
vector[count] = i
count += 1
return vector
建立样本库
需要取大量验证码图片提取单个字符图片作为训练集合,这一部分工作可以利用 二值化图片 和 分割图片 描述的方法,对搜集到的验证码进行处理的得到单个字符的图片,最终得到以下字符集对应的训练集合:
charset = ['0', '1', '2', '3','4', '5', '6', '7', '8', '9', '0', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
这里就不演示怎么见库了,可以使用实验楼老师ekCit 建立好的样本库:iconset
从样本库中建立训练数据集:
def load_iconset(iconset, dir_path='./iconset'):
'''加载训练集数据'''
imageset = []
for letter in iconset:
letter_dir = os.path.join(dir_path, letter)
for img in os.listdir(letter_dir):
temp = []
if '.gif' in img:
img_path = os.path.join(letter_dir, img)
letter_image = Image.open(img_path)
temp.append(build_vector(letter_image))
imageset.append({letter: temp})
return imageset
训练识别
有了样本库就可以进行训练识别了,下面是实现代码:
def guess_image_by(imageset, bimg):
'''根据样本数据识别'''
guess = []
v = VectorCompare()
for img in slice_image(bimg):
for image in imageset:
for x, y in image.items():
if len(y) != 0:
guess.append(( v.relation(y[0],build_vector(img)), x))
guess.sort(reverse=True)
yield guess[0]
识别函数
综合上述,编写识别方法:
def image_to_string(filename):
bimg = get_binary_image(filename)
iconset = [
'0', '1', '2', '3','4', '5', '6', '7', '8', '9',
'0', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i',
'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's',
't', 'u', 'v', 'w', 'x', 'y', 'z'
]
imageset = load_iconset(iconset)
s = ''
for guess_tuple in guess_image_by(imageset, bimg):
s += guess_tuple[1]
return s
测试
编写主函数内容:
if __name__ == '__main__':
print(image_to_string('code.gif'))
最终脚本内容参考:tools-with-script/pin2chars/pin_cracker.py
执行结果:
$ python3 pin_cracker.py
777ttt
恭喜我,以失败告终,崩溃。不过思路是对的,不知道哪里出了问题,先不研究了,主要目的还是练习python编程,有时间再说吧!
编写验证码识别器
实现
综合上面第三方库和自己实现的库,python3 实现一个命令行小工具,新建名为 pin2chars 的文件,内容如下:
#!/usr/bin/env python3
import os
import argparse
import pin_cracker
import pytesseract
import tesseract_ocr
from PIL import Image
def get_args():
'''得到命令参数
'''
parser = argparse.ArgumentParser()
parser.add_argument('-m', "--method", type=int, choices=[0, 1, 2], help='选择方法进行验证码的识别: 0. 使用 pin_cracker 库方法识别验证码; 1. 使用 pytesseract 库方法识别验证码; 2. 使用 tesseract_ocr 库方法识别验证码;')
parser.add_argument("imgfile", help='指定要识别的验证码图片')
return parser.parse_args()
def init_methods():
'''初始化方法列表
'''
methods = [
{
'method': pin_cracker.image_to_string,
'tip': 'pin_cracker 库的识别结果:'
},
{
'method': pytesseract.image_to_string,
'tip': 'pytesseract 库的识别结果:'
},
{
'method': tesseract_ocr.text_for_filename,
'tip': 'tesseract_ocr 库的识别结果:'
}
]
return methods
if __name__ == '__main__':
args = get_args()
methods = init_methods()
if os.path.isfile(args.imgfile):
if '.gif' in args.imgfile: # 避免 tesseract 读取 gif 图片出问题
filename = 'b_code.png'
Image.open(args.imgfile).convert('P').save(filename)
args.imgfile = filename
print(methods[args.method]['tip'], methods[args.method]['method'](args.imgfile))
else:
print('请给定有效图片路径!')
测试
(pin2chars-E2eD5P-4) ➜ pin2chars git:(master) ✗ ./pin2chars -m=0 code.gif
pin_cracker 库的识别结果: 777ttt
(pin2chars-E2eD5P-4) ➜ pin2chars git:(master) ✗ ./pin2chars -m=1 code.gif
pytesseract 库的识别结果: 7S9T9J’
(pin2chars-E2eD5P-4) ➜ pin2chars git:(master) ✗ ./pin2chars -m=2 code.gif
Info in pixReadStreamPng: converting (cmap + alpha) ==> RGBA
Info in pixReadStreamPng: converting 8 bpp cmap with alpha ==> RGBA
Warning. Invalid resolution 0 dpi. Using 70 instead.
tesseract_ocr 库的识别结果: 7S9T9J’
总结
本文实现了一个简单的验证码识别器,使用了三个方法,前两种使用现有库,后一种使用了分割图片 + 向量识别的方式简单实现了验证码的识别,通过本文熟悉了 argparse、pillow 等库的使用,通过实践练习了python的基本使用,Peace!这里的方法明显处理不了更加复杂的验证码,要想提升方法的适应性,还得增加新的判别方法,后续有时间的话再研究吧。
大佬厉害了
厉害
v1.5.2