python用法之字符串拼接和列表生成
今天聊一下python用法的技巧和思考:字符串的拼接方法和列表的生成技巧。
列表生成
如果让你生成从0~1000的平方组成的列表,你会有几种实现方法,现在我知道的可以归结为两种:
- 列表生成式;
- 循环追加;
循环追加
先说一下循环追加,这种其实就是比较直白的从c语言中过渡来的实现方式,代码如下:
L = []
for i in range(1000):
L.append(i**2)
列表生成式
而列表生成式只需要一行代码:
L = [x ** 2 for x in range(1000)]
对比
下面咱编写一组测试脚本对比一下这两种方式耗时,分别测试用两种方式生成同一列表,这个列表以0开始以指定数字结束,测试所用结束点为以下数字:
[200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
测算耗时使用timeit模块,最终得到两种方法下所用耗时,绘制相应对比曲线,编写脚本文件,内容:
#!/usr/local/bin/python3
import timeit
from matplotlib import pyplot as plt
def loop_generate_list(end):
'''循环生成
'''
L = []
for x in range(end):
L.append(x**2)
def generate_list(end):
'''列表生成式
'''
L = [x**2 for x in range(end)]
if __name__ == '__main__':
end_num = [x*200 for x in range(1, 11)]
t1 = [timeit.timeit('loop_generate_list(%d)' % x, setup='from __main__ import loop_generate_list', number=500) / 500 for x in end_num]
t2 = [timeit.timeit('generate_list(%d)' % x, setup='from __main__ import generate_list', number=500) / 500 for x in end_num]
plt.close("all")
plt.figure(figsize=(12,4))
plt.plot(end_num, t1, label="For-loop")
plt.plot(end_num, t2, label="list-generate")
plt.xlabel('the end number of list')
plt.ylabel('Escaped Time(s)')
plt.legend()
plt.show()
执行脚本以后会得到以下曲线:
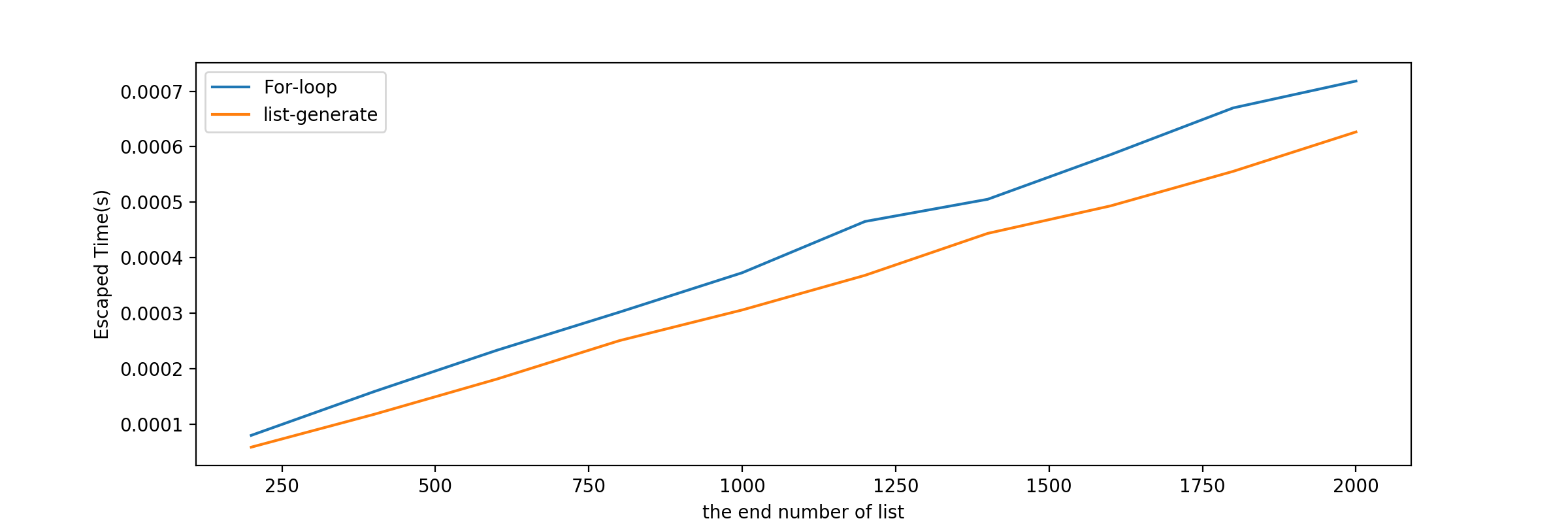
耗时数据如下:
列表 | 循环方式耗时(s) | 列表生成式耗时(s) ——-|————————| 0~199 | 7.943870799499565e-05 | 5.8151310004177506e-05 0~399 | 0.00015830999000172598 | 0.00011730378400534392 0~599 | 0.00023279044800437988 | 0.00018087501599802635 0~799 | 0.0003016821240016725 | 0.00025029307800286915 0~999 | 0.00037272097000095526 | 0.00030559123599960004 0~1199 | 0.000465159749990562 | 0.00036801772599574177 0~1399 | 0.0005052312600018923 | 0.0004436784459976479 0~1599 | 0.0005855820479919203 | 0.0004932414859940763 0~1799 | 0.0006699951940099709 | 0.0005555873200064525 0~1999 | 0.0007183871679881122 | 0.0006266429160023108
综上结果,列表生成式非但写法简单,而且执行速度也是比手动循环添加快,可以说是一种语法好糖了,建议都使用列表生成式生成自己想要的列表。
拼接字符串
字符串的拼接在python中很灵活,既可以用+运算符,又可以用格式化字符串,还能用join函数,那我们用哪一个比较好呢,这里咱先关心一下执行速度,所以就像第一节中一样比较一下哪种速度更快!
+号拼接
比如:
hello = 'hello, ' + 'Monkey!' + 'Let\'t' + 'Do' + 'it'
%号拼接
类似于c库中的sprintf
hello = '%s%s%s%s%s' % ('hello, ', 'Monkey! ', 'Let\'t ', 'Do ', 'it!')
format方法拼接
是python2.6中出现的用来替代%拼接字符串的方式。
hello = '{}{}{}{}{}'.format('hello, ', 'Monkey! ', 'Let\'t ', 'Do ', 'it!')
f-string方式拼接
f-string全称Formatted String Literals,也就是字面量格式化字符串,这是python3.6引入的,用法类似于前面%号拼接和format方法
str_l = ['hello, ', 'Monkey! ', 'Let\'t ', 'Do ', 'it!']
hello = f'{str_l[0]}{str_l[1]}{str_l[2]}{str_l[3]}{str_l[4]}'
可以说这种方式非常强大,会执行{}中的内容,将结果作为替代项,放置到相应位置。
join函数拼接
hello = ''.join(['hello, ', 'Monkey! ', 'Let\'t ', 'Do ', 'it!'])
对比
同样使用timeit模块评估运算时间, 这次看一下每种方法执行100000次用的时间:
#!/usr/local/bin/python3
import timeit
t1 = timeit.timeit("hello = 'hello, ' + 'Monkey!' + 'Just' + 'Do' + 'it'", number=100000)
print('+运算符拼接:', t1)
t2 = timeit.timeit("hello = '%s%s%s%s%s' % ('hello, ', 'Monkey! ', 'Just ', 'Do ', 'it!')", number=100000)
print('%操作符拼接:', t2)
t3 = timeit.timeit("hello = '{}{}{}{}{}'.format('hello, ', 'Monkey! ', 'Just ', 'Do ', 'it!')", number=100000)
print('Format方法拼接:', t3)
t4 = timeit.timeit("str_l = ['hello, ', 'Monkey! ', 'Just' , 'Do ', 'it!'];hello = f'{str_l[0]}{str_l[1]}{str_l[2]}{str_l[3]}{str_l[4]}'", number=100000)
print('f-string方法拼接:', t4)
t5 = timeit.timeit("hello = ''.join(['hello, ', 'Monkey! ', 'Just ', 'Do ', 'it!'])", number=100000)
print('join方法:', t5)
结果是:
+运算符拼接: 0.0016716789978090674
%操作符拼接: 0.02950063199386932
Format方法拼接: 0.054942579998169094
f-string方法拼接: 0.03282728197518736
join方法: 0.022729617019649595
可以看出小规模拼接短字符串时,使用+拼接更快速直接。
但是当需要大规模拼接很多长字符串时,会是什么情况呢?此时前面说的中间三个类似于格式化字符串的方式不太适合连续合并大量字符串,要实现要么代码长而粗暴,要么实现代码短但不高效。
那么就比较一下其余两种方法:
#!/usr/local/bin/python3
import timeit
def test_add_str():
hello = ''
for x in range(10000):
hello += 'hello, every body! Welcom here for our pretty moment! Thanks for that!\n'
def test_join_str():
str_test = 'hello, every body! Welcom here for our pretty moment! Thanks for that!\n'
str_list = [str_test for x in range(10000)]
hello = ''.join(str_list)
if __name__ == '__main__':
t1 = timeit.timeit('test_add_str()', setup='from __main__ import test_add_str', number=100) / 100
print('+运算符拼接:', t1)
t2 = timeit.timeit('test_join_str()', setup='from __main__ import test_join_str', number=100) / 100
print('join方法:', t2)
对比结果:
+运算符拼接: 0.0019161234499915736
join方法: 0.00045332342000619974
可以看到join方法的优势更明显。为什么会出现这样的结果呢?其实是两个方法的机制不一样,+运算符拼接的方法是每次拼接都会生成新的副本,拼接一次就有一次复制操作;而join方法是根据列表先预估空间,后面只需复制每次要拼接的字符串就好了,所以像这种规模大且数量多的字符串拼接还是选join方法比较合适。
总结
当拼接字符串短且少的时候使用+号拼接会是更快的实现,另外f-string的方式可能会比较灵活,而当拼接字符串变长或者数量增多的话,还是使用join效率更高。
v1.5.2