爬虫实践之头条狗狗图片
最近在学习爬虫,学了就应该多实践实践,本文将记录使用requests 库下载头条上搜到的狗狗图片的实现过程,使用python3实现。
前言
我们知道现在有部分网页访问的时候返回的并不是完整的html,其利用javascript获取局部数据最终实现完整页面的呈现,而这依赖的是AJAX技术:
AJAX,即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是一种创建交互式网页应用的网页开发技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
@W3Cschool AJAX简介
而头条的搜图页面也是采用 AJAX 技术,下面分析一下网页。
网页分析
首先,浏览器(本文使用的是google chrome)打开头条图片频道的网址:https://www.toutiao.com/ch/news_image 。打开页面会在右上角看到搜索框,在搜索框中输入狗狗,进行搜索,就会得到下面的页面:
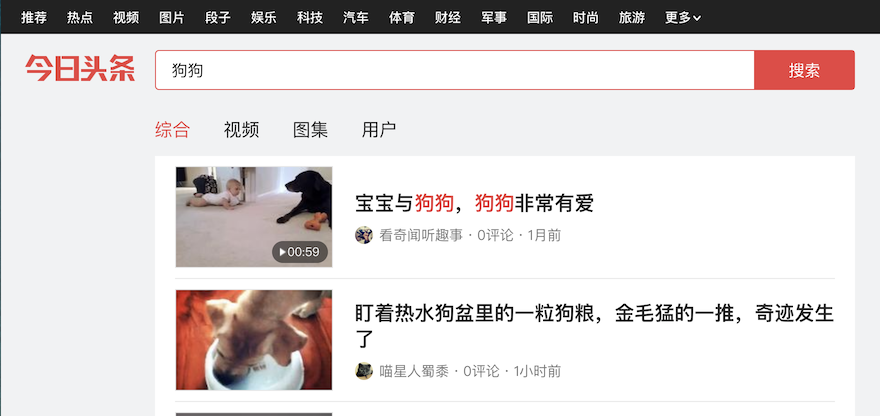
右击页面选择检查,就会出现一个网页检查窗口,有很多标签页,依次找到Network-XHR,此时点击上图页面中的图集,就会发现网页检查窗口中左栏出现一个XHR,如下:
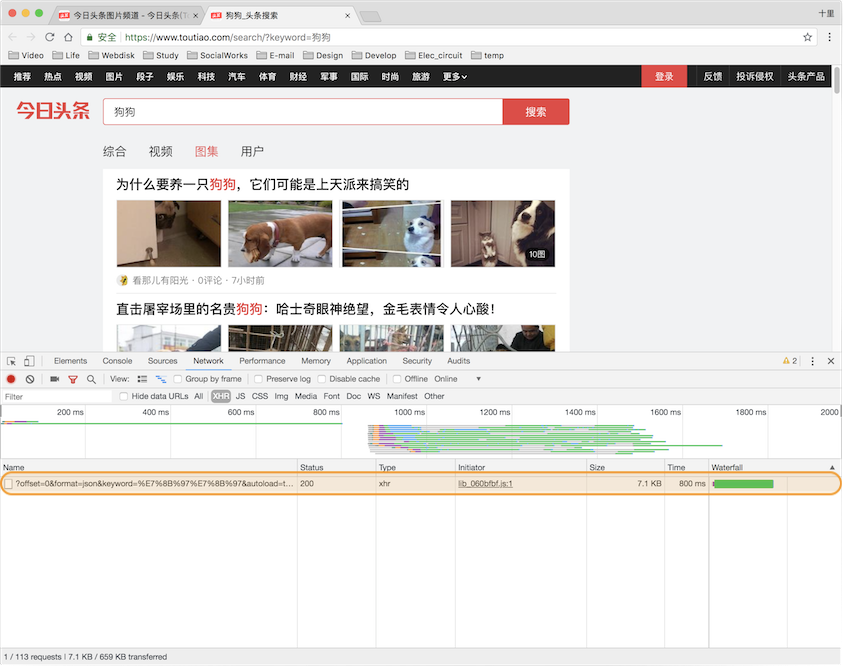
点击图中圈出的XHR,就会出现此条AJAX请求的详细内容,选择Headers 标签页:
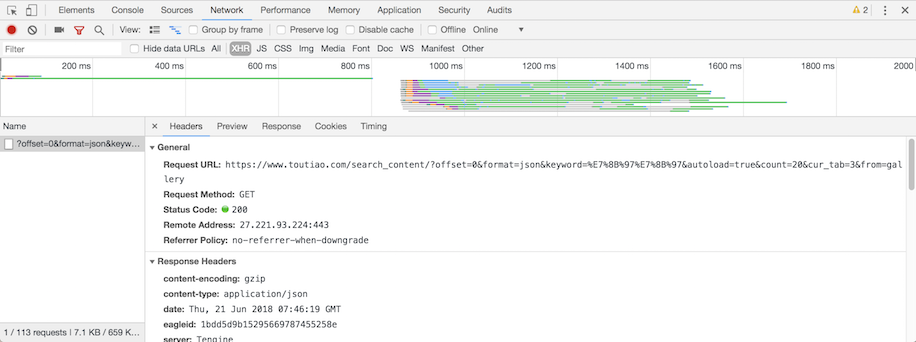
可以看到有请求头和响应头的信息,而 Preview 标签页内显示的则是请求结果,很明显的响应结果是个json格式的内容,chrome已经清晰的排版了json内容,对照网页呈现的内容查看一下json内容。
响应结果分析
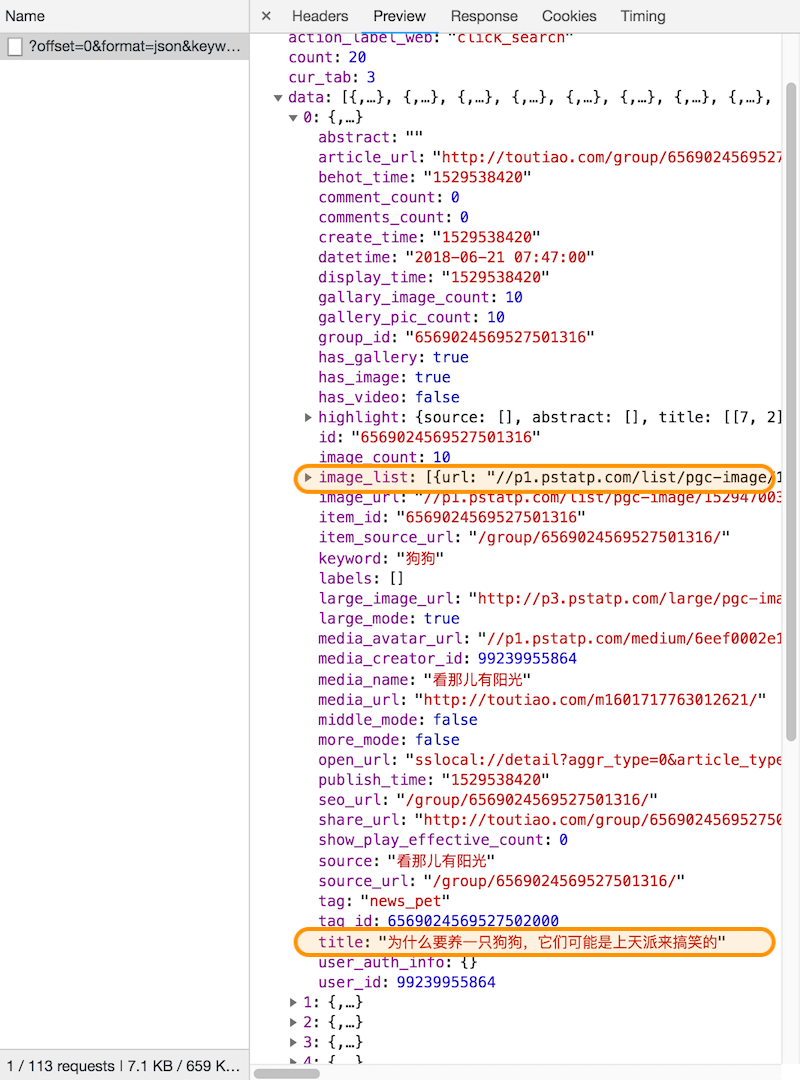
按照层级查看json内容,展开 data 就会发现有20个内容,正好与网页中显示的20个条目对应,展开 0 查看一下,可以看到两个关键信息:
title:对应网页条目的标题image_list: 对应网页中图片的链接
查看 data 中的其它项,会发现都是与网页显示内容的条目一一对应,这样就一目了然了,可以通过AJAX请求获取json内容,然后解析json内容中的data里每个条目里的 title和image_list就可以得到图片链接了,这样就可以根据链接获取图片了,那么还得分析一下AJAX请求有什么规律。
请求头分析
切换到Headers 标签页,可以看到Requests URL为:
滚动网页到最底以后,网页会增加20个新的条目,这时候会发现出现了一个新的 XHR,点击这个新的请求,查看头信息中的 Requests URL为:
同时查看 Preview 标签页里的json数据,会发现与网页中新增加的20个条目是对应的,同理在继续滚动加载,又会多一个XHR,响应的json与新增加的条目对应。
对比每次增加的XHR中的请求链接,会发现链接只有一个 offset 参数在变,一个比一个多20,不难想20其实就是对应了 count 参数,其中还有一个 keyword 参数,对应的汉字其实就是 狗狗,那么看到这儿也就明白了,请求链接可以通过改变 offset 参数来生成,请求回来的json数据中就包含了对应offset下的20条数据,然后解析数据得到相应标题下的所有图片链接就可以了。
爬虫实现
根据对网页的分析,就可以针对性的设计爬虫程序了。
爬虫思路
根据上一节的分析,可以分三步实现图片的爬取:
- 按照上一节分析的结果按照索引生成请求链接,请求网页获取响应结果;
- 从响应结果中提取关键信息:
- 标题
- 图片链接
- 根据图片链接获取图片,并保存到以标题进行命名的目录中;
库的选择
首先要生成请求链接,观察链接格式,可以选择库 urllibparse模块的方法 urlencode方法生成,然后选择 requests 库进行网页请求,返回的结果是json,其实对应的是字典数据,提取信息不需要额外的库,同样使用 requests 库请求图片链接获取图片,为了好管理图片还得生成目录,需要使用 os库。本地保存的话,为了防止命名冲突,这里根据图片数据的md5码命名,那么会用到 hashlib 库,总结会用到以下库和方法:
requestsurllib.parse的urlencodehashlib的md5os
上述库中,只需要安装requests和urllib这两个库,一般通过pip3安装。
$ pip3 install requests urllib
爬虫实现
首先将上述库和方法导入。
import requests
from urllib.parse import urlencode
from hashlib import md5
import os
请求页面内容
根据前面的分析,只需要更改网页链接中的 offset 参数就可以生成新的请求链接,为了提高封装性,这里将网页内容的获取过程定义为一个函数,参数为 offset,这里需要注意的是,为了防止被头条屏蔽IP或拒绝访问,这里还需要给出一定头信息,参考chrome检查窗口中看到的请求头的信息即可:
HEADERS = {
'Host': 'www.toutiao.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1 Safari/605.1.15',
'X-Requested-With': 'XMLHttpRequest'
}
请求链接中的参数使用urlencode方法进行封装处理,根据链接特征需要指定参数如下:
params = {
'offset': offset,
'format': 'json',
'keyword': '狗狗',
'autoload': 'true',
'count': '20',
'cur_tab': '3',
'from': 'gallery'
}
为了提高程序的鲁棒性,使用try-except处理异常,最终实现的函数如下:
def get_page_json(offset):
'''生成ajax请求,发出get请求,并获取响应结果,以字典的形式返回json数据
:params offset: 页面请求偏移值
:type offset: 能被20整除的整数
:return: 响应数据
:rtype: dict
'''
params = {
'offset': offset,
'format': 'json',
'keyword': '狗狗',
'autoload': 'true',
'count': '20',
'cur_tab': '3',
'from': 'gallery'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e)
使用get方法进行请求,如果正常的话,就会得到响应的json数据,最终函数返回json数据转换成的字典数据,如果出现异常就会返回None。
解析响应结果
上一步获得了一次请求的json数据,下面就该实现响应结果的解析了,因为得到的是字典,所以首先得到data键对应的值,是一个列表,对应包含20个条目的数据,遍历列表中的元素,每个元素都是字典,找到title键对应的值就是标题,image_list键对应的值是一个列表,列表中的元素就是链接关键信息,为链接信息加上协议组成正常的url字符串即可,将解析出来的每个链接和上层的标题共同组成一个字典返回,这里用yield方法生成迭代器,最终实现的函数如下:
def parse_images_url(json):
'''解析json字典,获得对应条目标题和图片链接
:param json: 页面请求响应结果对应的字典数据
:type json: dict
'''
data = json['data']
if data:
for item in data:
title = item['title']
images = item['image_list']
if images:
for image in images:
yield {
'image': 'http:' + image['url'],
'title': title
}
下载图片
得到了图片链接,那么我们就可以保存图片了,同样将保存图片的操作封装为一个函数。
思路很简单,为了更好的管理图片,生成以标题命名的目录用来保存图片,get请求图片链接,因为获取的是二进制数据,所以将响应结果按照二进制保存为文件,文件名则根据二进制数据计算md5生成文件名,实现中加入了多个信息判断以及try-except方式的处理,最终结果如下:
def save_image_from(image_info, to_dir=''):
'''根据链接获取图片,保存到标题命名的目录中,图片以md5码命名
:param image_info: 包含标题和链接信息的字典数据
:type image_info: dict
:param to_dir: 要保存到的目录,默认值是空字符串,可指定目录,格式如: '狗狗'
:type to_dir: unicode 字符串
'''
if image_info:
print(image_info)
image_dir = to_dir + '/' + image_info['title']
if not os.path.exists(image_dir):
os.makedirs(image_dir)
try:
response = requests.get(image_info['image'])
if response.status_code == 200:
image_path = '{0}/{1}.{2}'.format(image_dir, md5(response.content).hexdigest(), 'jpg')
print(image_path)
if not os.path.exists(image_path):
with open(image_path, 'wb') as f:
f.write(response.content)
print('图片下载完成!')
else:
print('图片已下载 -> ', image_path)
except requests.ConnectionError as e:
print('图片下载失败!')
except:
print('出现异常!')
可以看到函数还多了一个参数to_dir,这个参数用来指定目录,用来保存以标题命名的目录以及其目录下的图片。
编写主函数实现
每一次请求会收到20个条目的数据,这里我们以请求10次为例,也就是总共获取200个条目下的图片,实现如下:
# 请求数
PAGE_NUM = 10
if __name__ == '__main__':
for offset in [x * 20 for x in range(0, PAGE_NUM)]:
print('获取第', offset + 1, '~', offset + 20, '个条目...')
json = get_page_json(offset)
for image in parse_images_url(json):
save_image_from(image, to_dir='狗狗')
整合实现
将上述几部分的说明和实现进行整合:
#!/usr/local/bin/python3
# 确认上面的python3路径是否正确
import requests
from urllib.parse import urlencode
from hashlib import md5
import os
PAGE_NUM = 10
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.1 Safari/605.1.15',
'X-Requested-With': 'XMLHttpRequest'
}
def get_page_json(offset):
# 此处省略,参考前面的实现
def parse_images_url(json):
# 此处省略,参考前面的实现
def save_image_from(image_info, to_dir=''):
# 此处省略,参考前面的实现
if __name__ == '__main__':
# 此处省略,参考前面的实现
测试及优化
上述代码在脚本文件toutiao_pic.py中实现,执行脚本测试一下:
$ python3 toutiao_pic.py
获取第 1 ~ 20 个条目...
{'image': 'http://p3.pstatp.com/list/pgc-image/15296042422187b4c0bfb38', 'title': '史上最美的11对狗狗的结婚照,一张你都没见过!'}
狗狗/史上最美的11对狗狗的结婚照,一张你都没见过!/f56a49c55933be46f87f554d961841a9.jpg
图片下载完成!
{'image': 'http://p3.pstatp.com/list/pgc-image/152960424260924673d65ea', 'title': '史上最美的11对狗狗的结婚照,一张你都没见过!'}
狗狗/史上最美的11对狗狗的结婚照,一张你都没见过!/ca6973e7d891a48ade41477ef3944627.jpg
图片下载完成!
{'image': 'http://p3.pstatp.com/list/pgc-image/15296042427877f2cd0e93a', 'title': '史上最美的11对狗狗的结婚照,一张你都没见过!'}
狗狗/史上最美的11对狗狗的结婚照,一张你都没见过!/5317c8b27494c21f8e05936fd092c580.jpg
图片下载完成!
{'image': 'http://p3.pstatp.com/list/pgc-image/1529604243143d15de20946', 'title': '史上最美的11对狗狗的结婚照,一张你都没见过!'}
狗狗/史上最美的11对狗狗的结婚照,一张你都没见过!/d83f8de993ccba427d62138812cbc9bf.jpg
图片下载完成!
{'image': 'http://p1.pstatp.com/list/pgc-image/1529588142869caebf0b30d', 'title': '儿子打了狗狗一下,接下来让一家人感动'}
狗狗/儿子打了狗狗一下,接下来让一家人感动/c1f1880a9dff12cadeb5893715b7b5de.jpg
图片下载完成!
.
.
.
{'image': 'http://p1.pstatp.com/list/pgc-image/15268265312399549e4d5fe', 'title': '可爱的狗狗'}
狗狗/可爱的狗狗/808e74f76dea32fd56614b82c2d55b79.jpg
图片下载完成!
{'image': 'http://p3.pstatp.com/list/pgc-image/1526826535155011a163e03', 'title': '可爱的狗狗'}
狗狗/可爱的狗狗/df7a97475a5b62ad4f0545fbf64f91ed.jpg
图片下载完成!
{'image': 'http://p1.pstatp.com/list/pgc-image/15268265365385bfb3779ae', 'title': '可爱的狗狗'}
狗狗/可爱的狗狗/7e9ae7183132420a1a49b8f14032f7f9.jpg
图片下载完成!
{'image': 'http://p3.pstatp.com/list/pgc-image/15268265382025a24d029a8', 'title': '可爱的狗狗'}
狗狗/可爱的狗狗/8fa9fe7c4096e6b5026767f7cca9400e.jpg
图片下载完成!
获取第 181 ~ 200 个条目...
顺利的话,查看脚本同级目录中出现了狗狗 的目录,检查目录中确实按照预期爬取了图片。
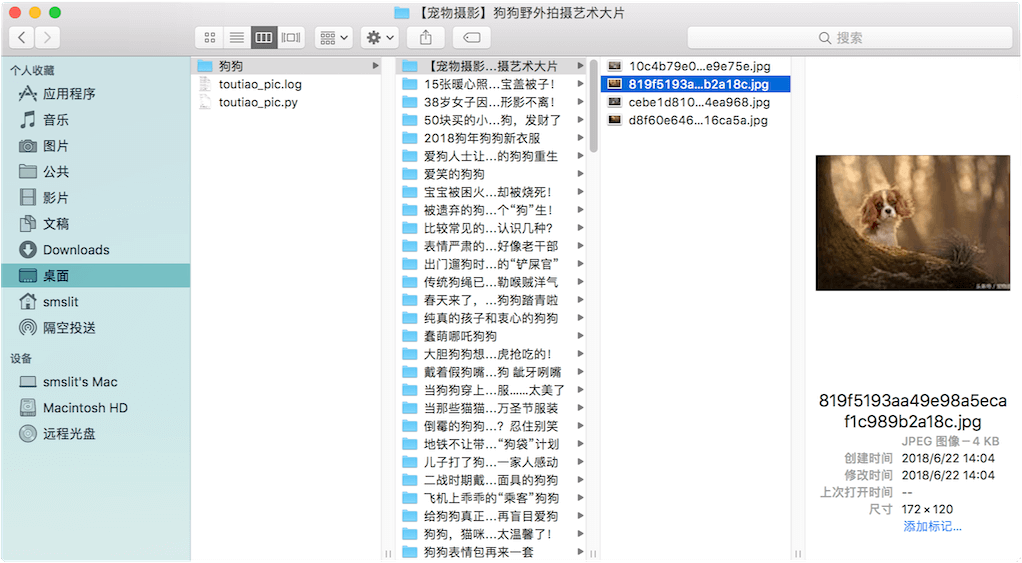
结果分析
针对成果,总结分析有三点需要改进的地方:
- 图片分辨率低:查看图片,你会发现分辨率很低,有的几乎看不清;
- 没有使用多进程爬取;
- 脚本不够通用,能不能像命令一样执行,实现可以搜索任意想搜索的图片,而不仅仅局限于🐶;
优化
图片分辨率问题
还是得分析网页,找到狗狗图集的页面,以第一个条目的第一个图片为例,看看有什么规律可循。
记录json数据中第一个图片的链接为:
http://p1.pstatp.com/list/pgc-image/15296042422187b4c0bfb38
点击第一个条目,进入相应图集,还是看第一个图,这是发现图片分辨率明显提高,那么此时这个图片的链接是什么,查看一下为:
http://p3.pstatp.com/origin/pgc-image/15296042422187b4c0bfb38
比较两个链接,发现有两个不同的地方:
| 图片链接 | 主机名 | 目录名 |
|---|---|---|
| 低分辨率 | p1 | list |
| 高分辨率 | p3 | origin |
更改低分辨率图片链接中的p1为p3,用浏览器去访问,居然也能出图片,但还是低分辨率,看来这个不关键,那只更改list为origin试一下,居然可以访问,而且是高分辨率的图片。
以此方式比较几张其它图片的链接,发现均可以只改链接中的list为origin就能得到高分辨率的图片,那么优化函数parse_images_url中的image链接生成的那一行代码,调用字符串替换函数replace就可以,如下:
# 原代码
'image': 'http:' + image['url'],
# 改进后代码
'image': 'http:' + image['url'].replace('list', 'origin'),
重新运行脚本,检查图片,结果可行!
多进程爬取
这里采用多进程库multiprocessing的进程池实现多进程调度,为了方便映射,将主函数中的实现,封装为main函数,参数用来进程分配,所以为offset,main函数实现如下:
def main(offset):
'''主函数,用于多进程调度
:param offset: 页面链接offset参数的值
:type offset: 能被20整除的整数
'''
print('获取第', offset + 1, '~', offset + 20, '个条目...')
json = get_page_json(offset)
for image in parse_images_url(json):
save_image_from(image, to_dir='狗狗')
引入多进程库:
from multiprocessing.pool import Pool
生成进程池,映射主函数并执行,最终实现如下:
if __name__ == '__main__':
offset_list = [x * 20 for x in range(0, PAGE_NUM)]
pool = Pool()
pool.map(main, offset_list)
pool.close()
pool.join()
执行后,看打印信息,会发现会有多个请求同时进行,速度明显加快。
通用化脚本
这里说通用化,也仅局限于获取头条中的图集,目前根据前面分析,链接中可以更改的除了offset,其实还有个keyword,其它的目前来看没必要更改了,说起来其中count应该也可以修改,这里有个假设:
offset与count有关,offset值要能被count整除;- 响应结果中条目数与
count对应
上面的假设就不验证了,留给感兴趣的人吧,这里只做
offset和keyword的定制实现。
稍微修改get_page_json函数和main函数,加入keyword参数用来指定搜索关键词:
def get_page_json(offset, keyword):
'''生成ajax请求,发出get请求,并获取响应结果,以字典的形式返回json数据
:param offset: 页面请求偏移值
:type offset: 能被20整除的整数
:param keyword: 图片搜索的关键词
:type keyword: unicode字符串
:return: 响应数据
:rtype: dict
'''
params = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': '3',
'from': 'gallery'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e)
def main(offset, keyword):
'''主函数,用于多进程调度
:param offset: 页面链接offset参数的值
:type offset: 能被20整除的整数
:param keyword: 图片搜索关键词
:type keyword: unicode字符串
'''
print('获取第', offset + 1, '~', offset + 20, '个条目...')
json = get_page_json(offset, keyword)
for image in parse_images_url(json):
save_image_from(image, to_dir=keyword)
能不能做成类似于命令行的方式传入搜索的关键词呢?当然可以了,首先在脚本文档最前面加上如下的代码,用来指明所使用的python路径,例如十里的是:
#!/usr/local/bin/python3
然后为脚本文件加上执行权限:
$ chmod +x toutiao_pic.py
这样你就可以像命令一样执行脚本了:
$ ./toutiao_pic.py
这里实现一个简单的参数设置思路,规定必须输入两个参数,一个是关键词,一个是请求个数,所以固定命令的格式为:
./toutiao_pic.py 狗狗 5
即命令后跟着第一个参数就是图片搜索的关键词,然后就是请求个数的设置,如果要提取这两个参数,需要用到sys库的argv,在脚本中sys.argv是一个字符串列表,第一个元素就是命令,在这里的话,如果输入命令格式正确,那么这个列表会包含三个元素,后两个按顺序分别是:图片搜索关键词和请求个数(每个请求会得到20个图集信息),为了更好的交互,还得加入一定的帮助信息的打印,所以最终添加了以下代码:
def get_help_info(command):
'''生成帮助信息
:param command: 命令的名称
:type command: 字符串
'''
help_info = '\n使用:\n ' + command + ' 关键字 请求个数\n'
help_info += ' - 关键字: 图片搜索关键词\n - 请求个数: 一次请求会获取20个图集的图片\n'
help_info += '例如:\n ' + command + ' 狗狗 5\n -> 会获取100个图集中狗狗的图片\n'
return help_info
def parse_argv(args=sys.argv):
'''解析命令参数
'''
args_dict = {
'-h': get_help_info(args[0]),
'-k': '狗狗',
'-n': PAGE_NUM
}
if len(args) != 3:
print(args_dict['-h'])
sys.exit(0)
else:
try:
page_num = int(args[2])
args_dict['-n'] = page_num if page_num <= 100 else 5
args_dict['-k'] = args[1]
except ValueError:
print('请求个数有误,请输入整数')
sys.exit(0)
return args_dict
此时会有一个问题,那就是main函成为了有两个参数函数,进程池map的处理需要调整。先看一下现在程序的执行思路:先解析命令参数获得关键词和请求个数,然后传入main函数进行处理。进程池的map只能管理单个参数的函数,那么现在的问题就是解决进程池的map的多参数处理,应该有多个方法,可以发现main函数执行的话每次传入的图片搜索关键词是一定的,那么可以利用functools库的partial类构造一个只有offset这个参数的partial函数,实现过程:
if __name__ == '__main__':
args_dict = parse_argv()
offset_list = [x * 20 for x in range(0, args_dict['-n'])]
pool = Pool()
partial_main = partial(main, keyword=args_dict['-k'])
pool.map(partial_main, offset_list)
pool.close()
pool.join()
总结
至此,所有代码已经完成,为了让脚本用起来更像命令行工具,可以把后缀名py去掉,然后想一个好名字重命名一下,比如这样:
$ mv toutiao_pic.py ttpic
$ ./ttpic
使用:
./ttpic 关键字 请求个数
- 关键字: 图片搜索关键词
- 请求个数: 一次请求会获取20个图集的图片
例如:
./ttpic 狗狗 5
-> 会获取100个图集中狗狗的图片
如果我们想要爬取猫咪的图片,另外想要获取100个图集的,请求个数设置为 $100\div20=5$ ,最终命令为:
$ ./ttpic 猫咪 5
完整代码可参考: ttpic